The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations
The DevOps Handbook isn't just another tech methodology book. It's the definitive guide to why some engineering teams ship fast without breaking everything, while others are stuck in deployment hell. If you've ever wondered how companies like Netflix and Amazon deploy thousands of times per day without catastrophic failures, this book reveals the playbook.

The Bible of Modern Software Delivery
Introduction: Why Most Engineering Teams Are Still Doing It Wrong
The DevOps Handbook addresses one of the most painful patterns in software engineering: the Friday afternoon deployment that turns into a weekend disaster. Code freezes, frantic rollbacks, passive-aggressive executive emails about reliability commitments. Most teams have lived this nightmare.
This book presents a fundamentally different approach to software delivery. Not radical new concepts—most ideas have been around for decades—but a coherent, proven methodology backed by real case studies from companies that deploy code hundreds or thousands of times per day without catastrophic failures.
The authors (Gene Kim, Jez Humble, Patrick Debois, and John Willis) aren't academics theorizing from ivory towers. They've built and studied high-performing technology organizations. The book is dense with practical patterns, anti-patterns, and actual implementation details.
What makes this essential reading:
Case Study Heavy: Every principle is illustrated with real examples from companies like Netflix, Amazon, Google, Etsy, and Target. Not hypothetical scenarios. Actual transformations with metrics.
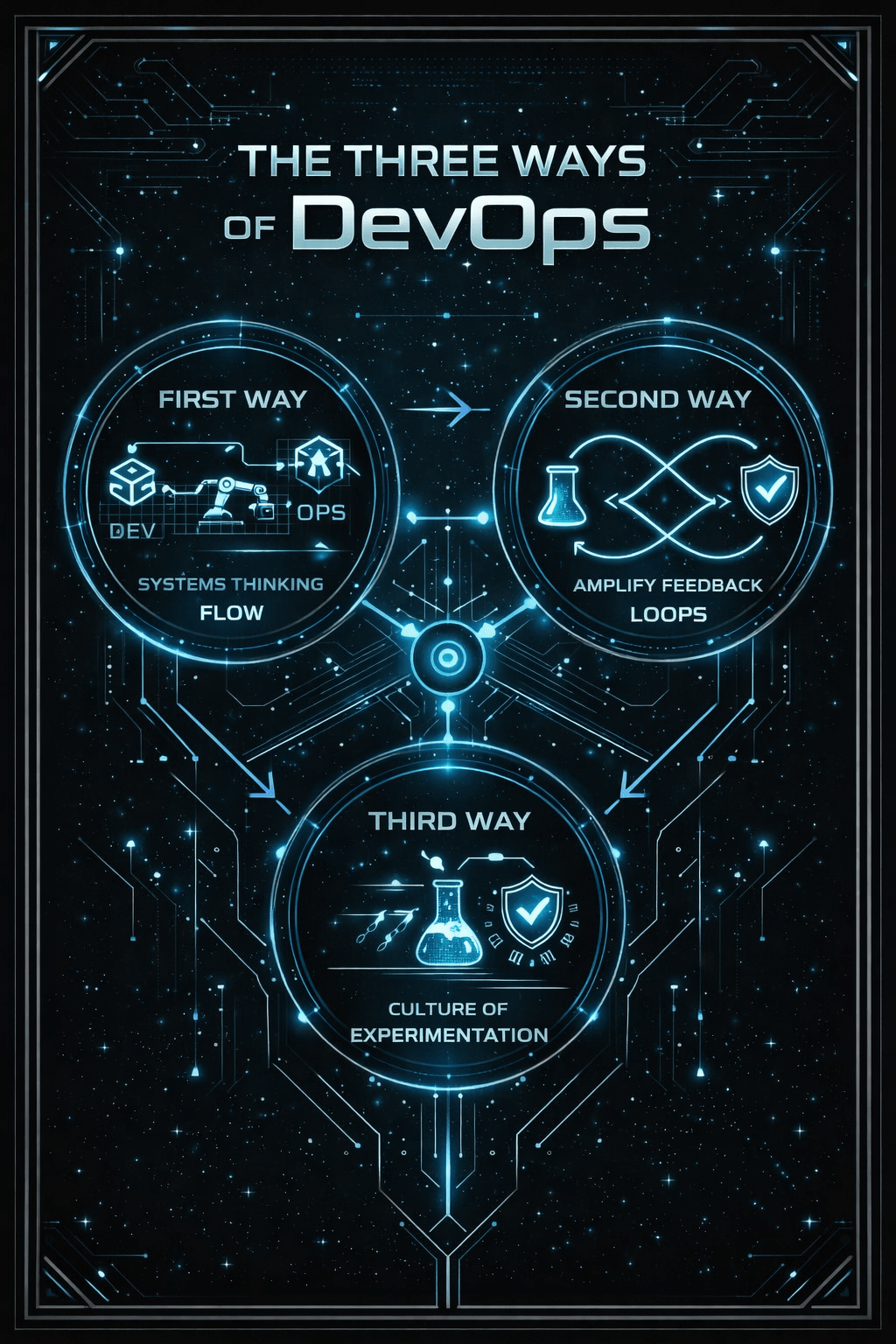
The Three Ways Framework: Flow, Feedback, and Continuous Learning. A simple mental model that applies to everything from CI/CD pipelines to organizational structure.
Implementation Roadmap: This isn't just philosophy. Part 2 is titled "Where to Start" with specific steps for beginning your transformation.
Cultural Transformation: The hardest part of DevOps isn't the tools. It's changing how teams interact. The book dedicates significant space to the human and organizational challenges.
Honest About Failure: Includes stories of transformations that failed and why. Refreshingly realistic about the difficulty of change.
For anyone building software products, managing engineering teams, or trying to understand why some tech companies move fast while others are mired in bureaucracy, this book is required reading. (Buy on Amazon)
Book Details at a Glance
| Feature | Details |
|---|---|
| Title | The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations |
| Authors | Gene Kim, Jez Humble, Patrick Debois, John Willis |
| Publication Year | 2016 (still highly relevant) |
| Genre | Technology, Software Engineering, Business Process, Organizational Design |
| Length | ~480 pages (comprehensive but readable) |
| Main Themes | Continuous delivery, Feedback loops, Organizational culture, Systems thinking |
| Key Concept | DevOps as the integration of development and operations into high-trust, high-collaboration teams |
| Relevance Today | Critical for modern software development, especially with AI/ML ops, cloud-native architectures |
| Readability | Dense with information but well-structured, case studies make concepts concrete |
| Who Should Read? | Engineering leaders, DevOps practitioners, CTOs, product managers, anyone shipping software |
Breaking Down the Book: The Three Ways and Beyond
The book is structured around "The Three Ways"—a mental framework that governs all DevOps practices. Everything else flows from these principles.
- The First Way: The Principles of Flow
Flow is about optimizing the entire system from code commit to production delivery, not just individual silos. Traditional organizations optimize for local efficiency. Each team working at 100% capacity. This paradoxically creates global inefficiency: bottlenecks, queues, handoffs.
Key practices:
- Continuous integration and deployment
- Small batch sizes (deploy small changes frequently)
- Automated testing at every stage
- Making work visible (Kanban boards, metrics dashboards)
- Limiting work in progress
The counterintuitive insight: large batch sizes feel efficient but create massive risk and slow feedback. Small batches feel inefficient but enable rapid learning and reduce blast radius.
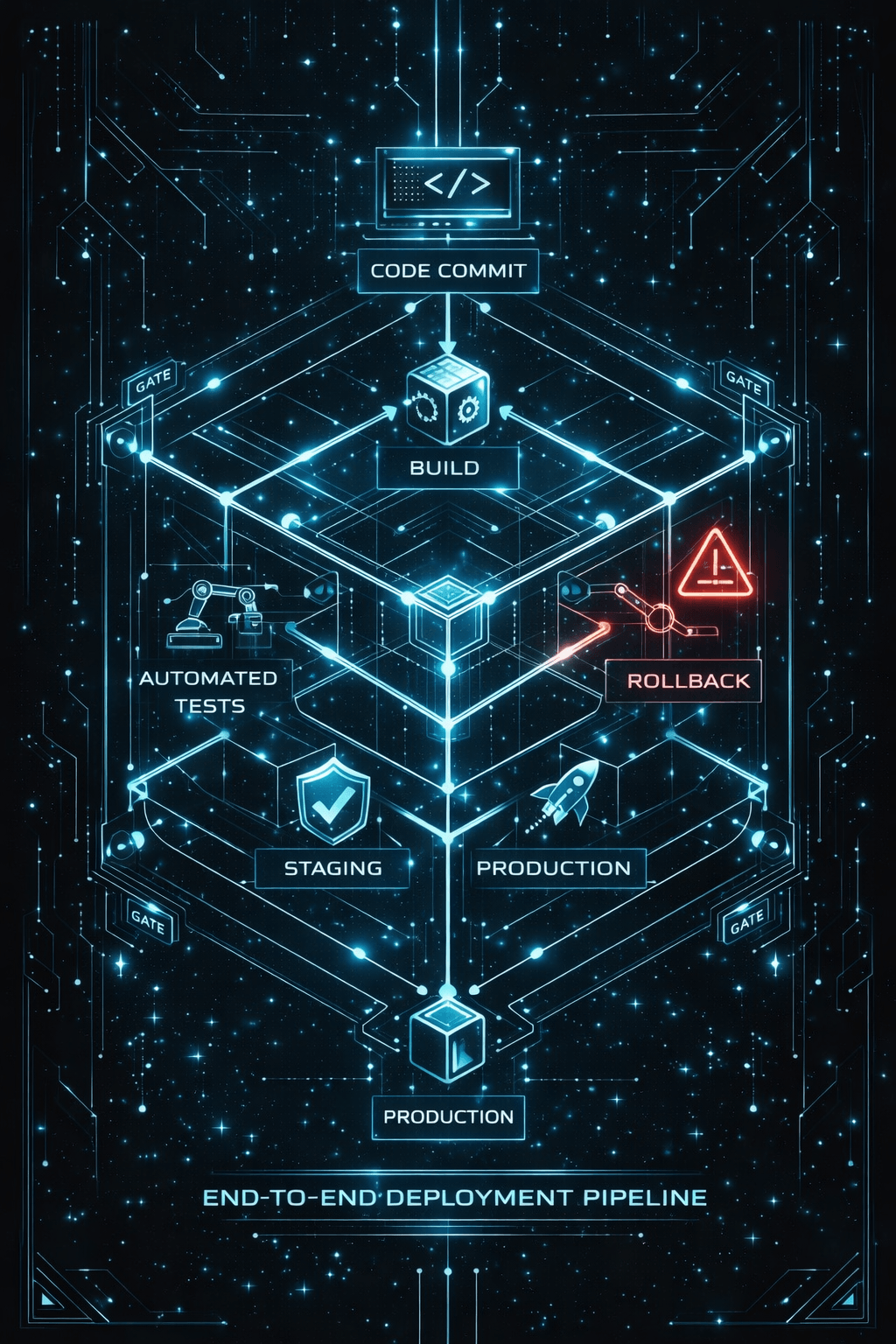
Implementation pattern: Teams transitioning from monthly releases to daily deploys typically use feature flags and automated rollback. The first month is terrifying. By month three, deployments become boring—which is exactly the goal. Mean time to recovery often drops from hours to minutes because teams practice recovery constantly rather than treating failures as rare catastrophes.
- The Second Way: The Principles of Feedback
Fast feedback loops at every stage prevent problems from compounding. The longer it takes to discover a defect, the exponentially more expensive it becomes to fix.
Key practices:
- Monitoring and telemetry (instrument everything)
- Hypothesis-driven development (treat features as experiments)
- Peer review and automated code analysis
- Production monitoring and alerting
- Blameless post-mortems
The book makes a compelling case that you should be able to detect and respond to problems faster than customers notice them. This requires treating monitoring as a first-class concern, not an afterthought.

Honest critique: The monitoring and observability section feels dated given the explosion of modern tools like OpenTelemetry, Honeycomb, and Datadog. The principles are timeless, but specific tool recommendations from 2016 need updating. Still, the conceptual framework is solid.
- The Third Way: The Principles of Continuous Learning and Experimentation
High-performing organizations create cultures where learning from failure is expected, not punished. This requires psychological safety, time for experimentation, and institutionalizing improvement.
Key practices:
- Allocate time for learning and improvement (Google's 20% time, Spotify's hack weeks)
- Blameless post-mortems focused on system improvements
- Chaos engineering (deliberately breaking things to test resilience)
- Encouraging risk-taking and learning from failures
- Knowledge sharing and documentation
The Netflix case study here is illuminating. They intentionally inject failures into production using Chaos Monkey to ensure their systems can handle real failures gracefully. Most organizations do the opposite. Try to prevent all failures, then panic when inevitable failures occur.
Real-world application: Many organizations now run "Game Days" where they simulate production failures—database crashes, API partner outages, traffic spikes. These exercises are painful at first, but they transform on-call engineers from terrified to confident. After practicing recovery dozens of times in controlled settings, real incidents become manageable rather than catastrophic.
- The Technical Practices: How to Actually Implement This
Part 3 gets tactical with specific patterns:
- Deployment pipelines: Automated path from commit to production
- Automated testing: Unit, integration, performance, security tests
- Continuous integration: Everyone commits to trunk daily
- Infrastructure as code: Terraform, CloudFormation, Ansible
- Database migrations: How to evolve schemas without downtime
- Feature flags: Deploy dark, then progressively enable
This section is valuable for practitioners. Understanding the philosophy is one thing. Knowing how to actually implement CI/CD when you have a legacy monolith and a database that can't go down is another.
The authors don't pretend it's easy. They acknowledge that most organizations have significant technical debt and architectural constraints. But they provide patterns for incremental improvement. You don't need to rewrite everything to start getting benefits.
Why This Book Matters Even More in 2026
Written in 2016, you might think the DevOps Handbook is dated. Nope. If anything, it's more relevant now:
AI/ML Operations: Same principles apply to MLOps. You need automated pipelines for training, testing, and deploying models. Fast feedback on model performance. Continuous learning from production data.
Cloud-Native Everything: The book's emphasis on infrastructure as code and automated deployments is now table stakes for cloud development.
Security as Code: DevSecOps is just DevOps principles applied to security—shift security left, automate security testing, make security feedback fast.
Platform Engineering: The hot new trend of building internal developer platforms is literally applying DevOps principles to infrastructure and tooling.
The book occasionally shows its age with some tool recommendations and less emphasis on containers and Kubernetes. But the core principles are timeless. They're about systems thinking and organizational design, not specific technologies.
One warning: This is not a light read. It's comprehensive, detailed, and assumes you're serious about transformation. If you want quick DevOps tips for faster deploys, read a blog post. If you want to fundamentally change how your organization builds and ships software, read this book cover to cover.
Final Thoughts & Where to Buy
⭐ Rating: 5/5. The definitive guide to modern software delivery. Should be required reading for anyone in a technology leadership role.
This book doesn't just teach you DevOps practices. It teaches you how to think about software delivery as a continuous improvement system. The case studies prove these aren't theoretical ideas. They're battle-tested patterns from companies operating at massive scale.
Who should skip this: If you're a solo developer or working on a simple project with no team, much of this will be overkill. Start with simpler CI/CD tutorials.
Who needs this: Engineering managers, platform engineers, CTOs, tech leads, anyone responsible for reliability and velocity at scale. Even if you don't implement everything, understanding these principles will make you better at your job.
📖 Buy The DevOps Handbook on Amazon
Pro tip: Read this alongside The Phoenix Project, a novel by the same lead author, which tells a DevOps transformation story. The novel makes the concepts sticky. The handbook makes them actionable. Together, they're the complete DevOps education.
Related Reading
From the Essays:
How these DevOps principles apply to AI-assisted development:
- AI Development Revolution Part 2: The Methodology - The AAA Framework (Autonomous, Adaptive, Agile) for modern development
- AI Development Revolution Part 3: Infrastructure - Infrastructure as code and automated deployment at scale
- The Multithreaded Mind: Six Weeks Living at Machine Speed - What happens when development velocity increases 10x
From the Journal:
- Decan 26: Corner Star Discernment - DevOps coordination and year-end release planning in practice
This post contains affiliate links. If you purchase through these links, I may earn a small commission at no extra cost to you. Thank you for supporting this blog!